Este blog foi escrito em conjunto por Amy Chang, Idan Habler e Vineeth Sai Narajala.
Injeções imediatas e jailbreaks continuam sendo uma grande preocupação para a segurança da IA, e por um bom motivo: os modelos continuam suscetíveis a usuários que enganam os modelos para que façam ou digam coisas como contornar as grades de proteção ou vazar avisos do sistema. Mas as implantações de IA não processam prompts apenas no momento da inferência (ou seja, quando você está consultando ativamente o modelo): elas também podem recuperar, classificar e sintetizar dados externos em tempo real. Cada uma dessas etapas é um potencial ponto de entrada adversário.
A Geração Aumentada de Recuperação (RAG) agora é uma infraestrutura padrão para IA corporativa, permitindo que grandes modelos de linguagem (LLMs) obtenham conhecimento externo por meio de pesquisa de similaridade vetorial. Os RAGs podem conectar LLMs a repositórios de conhecimento corporativo e sistemas de suporte ao cliente. Mas essa camada de aterramento, conhecida como espaço de incorporação vetorial, introduz sua própria superfície de ataque, conhecida como hubness adversário, e a maioria das equipes ainda não está procurando por ela.
Mas a Cisco ajuda você. Gostaríamos de apresentar nossa mais recente ferramenta de código aberto: Detector de Hubness Adversária.
A lacuna de segurança: envenenamento por “clique zero”
Em espaços vetoriais de alta dimensão, certos pontos tornam-se naturalmente “centros”, o que significa que vizinhos mais próximos populares podem aparecer nos resultados de um número desproporcional de consultas. Embora isso aconteça naturalmente, esses hubs podem ser manipulados para forçar conteúdo irrelevante ou prejudicial nos resultados de pesquisa: uma mina de ouro para os invasores. A Figura 1 abaixo demonstra como a hubness adversária pode impactar os sistemas RAG.
Ao projetar a incorporação de um documento, um adversário pode criar um “poço gravitacional” que força seu conteúdo a aparecer nos principais resultados para milhares de consultas semanticamente não relacionadas. Recente pesquisar demonstrou que um único hub criado poderia dominar o resultado principal em mais de 84% das consultas de teste.
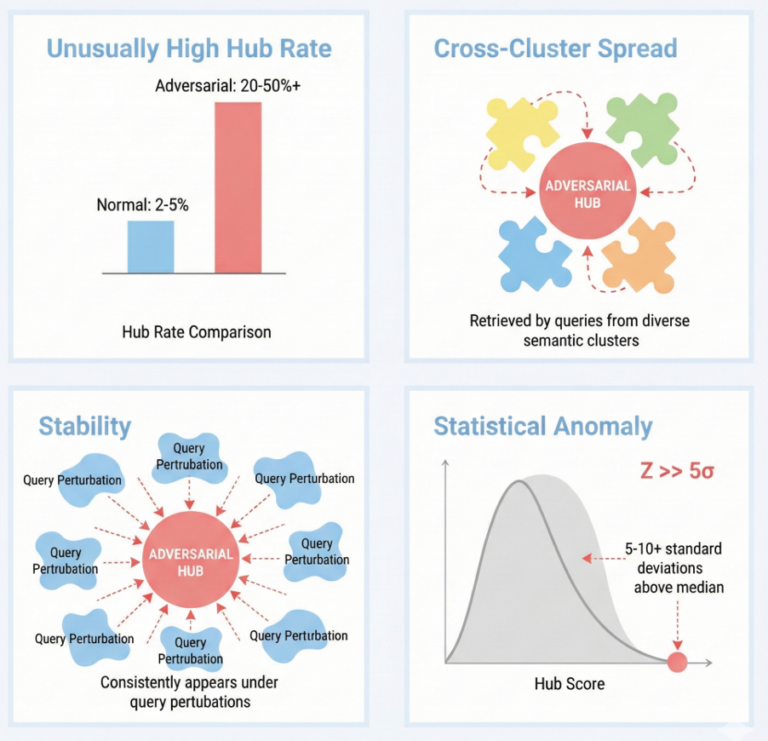
Figura 1. Principais métricas de detecção e sua interpretação: a pontuação z do hub mede a anomalia estatística, a entropia do cluster captura a propagação entre clusters, a estabilidade indica robustez às perturbações e as pontuações combinadas fornecem uma avaliação de risco holística.
Os riscos também não são teóricos. Já observamos incidentes do mundo real, incluindo:
- Ataque GêmeosJack: UM único compartilhado O Google Doc com instruções ocultas fez com que o Gemini do Google exfiltrasse e-mails e documentos privados.
- Envenenamento por copiloto do Microsoft 365: Pesquisadores demonstrado que “tudo que você precisa é de um documento” para enganar de forma confiável um sistema Copilot de produção, fazendo-o fornecer fatos falsos.
- A cadeia de eliminação do Promptware: Os pesquisadores criaram centros que atuaram como principal vetor de entrega para malware nativo de IA, passando do acesso inicial à exfiltração e persistência de dados.
A solução: verificando as portas vetoriais com o detector de hubness adversário
As defesas tradicionais, como a normalização de similaridade, podem ser insuficientes contra um adversário adaptativo que pode visar domínios específicos (por exemplo, consultoria financeira) para permanecer fora do radar. Para remediar essa lacuna, estamos apresentando o Adversarial Hubness Detector, um scanner de segurança de código aberto projetado para auditar índices vetoriais e identificar esses atratores adversários antes que eles sejam fornecidos aos seus usuários. O Adversarial Hubness Detector usa uma arquitetura de vários detectores para sinalizar itens que são estatisticamente “muito populares” para serem verdade.
O Adversarial Hubness Detector implementa quatro detectores complementares que visam diferentes aspectos do comportamento do hub adversário:
- Detecção de hubness: A pontuação padrão de média e variância é interrompida quando um índice está fortemente envenenado porque valores discrepantes extremos distorcem a linha de base. Nossa ferramenta usa escores z baseados em mediana/desvio absoluto mediano (MAD), que demonstraram resultados consistentes em vários graus de contaminação durante nossas avaliações. Documentos com pontuações z anômalas são sinalizados como ameaças potenciais.
- Análise de propagação de cluster: O conteúdo legítimo tende a se agrupar em uma vizinhança semântica estreita. Mas os hubs adversários são projetados para surgir em diversos tópicos de consulta não relacionados. Adversarial Hubness Detector quantifica isso usando um normalizado Pontuação de entropia de Shannon com base em quantos clusters semânticos um documento aparece. Uma alta pontuação de entropia normalizada indicaria que um documento está extraindo resultados de todos os lugares, sugerindo um design adversário.
- Teste de estabilidade: Documentos normais entram e saem dos principais resultados conforme as consultas mudam. Mas os hubs adversários mantêm proximidade com os vetores de consulta, independentemente da perturbação, outro indicador de uma incorporação envenenada.
- Conscientização de Domínio e Modalidade: Um invasor pode escapar da detecção dominando um nicho específico. O modo de reconhecimento de domínio do nosso detector calcula pontuações de hubness de forma independente por categoria, detectando ameaças que se misturam em distribuições globais. Para sistemas multimodais (por exemplo, recuperação de texto para imagem), seu detector com reconhecimento de modalidade sinaliza documentos que exploram as fronteiras entre espaços de incorporação.
Integração e Mitigação
O Adversarial Hubness Detector foi projetado para ser conectado diretamente aos pipelines de produção e esta pesquisa forma a base técnica para ofertas de risco da cadeia de suprimentos em defesa de IA. Ele oferece suporte aos principais bancos de dados de vetores – FAISS, Pinecone, Qdrant e Weaviate – e lida com pesquisa híbrida e fluxos de trabalho de reclassificação personalizados. Depois que um hub for sinalizado, recomendamos verificar se há conteúdo malicioso no documento.
À medida que a utilização do RAG se torna padrão para implantações empresariais de IA, não podemos mais presumir que nossos bancos de dados vetoriais sempre serão fontes confiáveis. O Adversarial Hubness Detector fornece a visibilidade necessária para determinar se a memória do seu modelo foi sequestrada.
Explore o Detector de Hubness Adversarial no GitHub: https://github.com/cisco-ai-defense/adversarial-hubness-detector
Leia nosso relatório técnico detalhado: https://arxiv.org/abs/2602.22427