Os ambientes industriais estão entrando na era da IA Física. Impulsionada por visão mecânica, veículos autônomos e automação definida por software, essa nova inteligência se baseia em milhares de PLCs, IHMs, controladores de segurança e acionamentos de motor já conectados em rede. Como cada parte do chão de fábrica está agora hiperconectada, maximizar o tempo de atividade da rede não é mais opcional – é uma obrigação comercial crítica.
Embora as anomalias de rede sejam inevitáveis, a solução de problemas eficaz é essencial para minimizar o tempo médio de detecção (MTTD) e resolução (MTTR).
A lacuna na solução de problemas de redes industriais
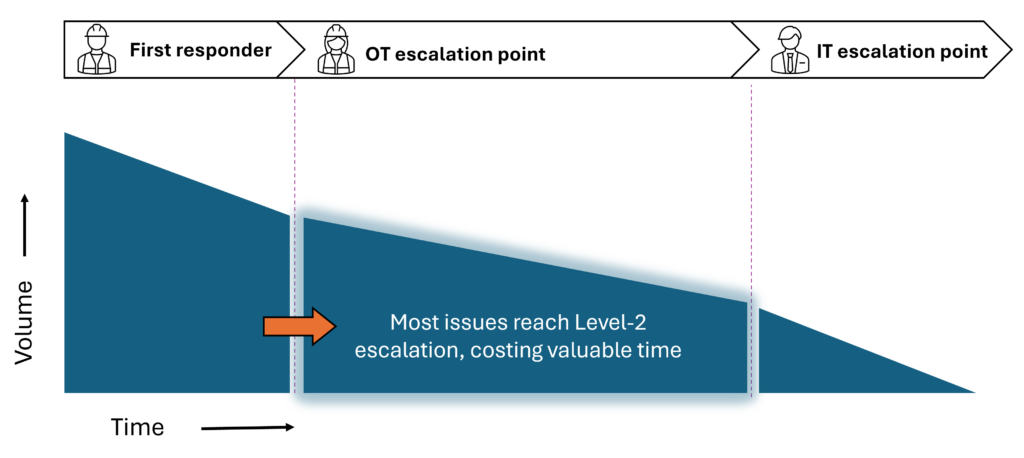
- As abordagens atuais são lentas para o chão de fábrica. Quando um problema interrompe a produção, cada minuto conta. Mas a solução de problemas atual é amplamente reativa – os problemas surgem quando uma linha é interrompida ou um dispositivo fica inacessível e então a investigação começa. A correlação de problemas com a causa raiz é manual, distribuída por diversas ferramentas e depende de quem estiver disponível. Em um ambiente onde o tempo de inatividade é medido em dezenas de milhares de dólares por minuto, esse processo não é rápido o suficiente.
- Muitas escaladas para poucos especialistas. O socorrista – o técnico de manutenção no local – conhece os sistemas físicos, mas tem dificuldade para diagnosticar quando um problema está relacionado à rede. As ferramentas de TI carecem de contexto de TO suficiente para ajudar, e os técnicos de TO não têm conhecimento de rede para usar essas ferramentas. Mesmo problemas simples – por exemplo, um endpoint OT que foi movido acidentalmente para uma porta diferente, fazendo com que ele ficasse off-line – são escalados porque o socorrista não consegue determinar a causa raiz. O ponto de escalonamento de TO – a equipe de especialistas em rede que absorve esses escalonamentos é pequena e está espalhada por vários locais.
O resultado: horas de inatividade da produção enquanto os especialistas se atualizam. Para problemas de camada física – um cabo danificado, um transceptor de fibra óptica com defeito – a solução geralmente é simples o suficiente para que o técnico no local possa agir diretamente, se conseguir chegar à causa raiz. Para problemas de operações de rede, ainda são necessários especialistas em rede – mas a lacuna é a mesma: passar do problema à causa raiz com rapidez suficiente para manter a linha em movimento.
Como parte do Cisco AgenticOps e disponível por meio do Cisco Cloud Control, o AI Troubleshooting for Industrial Networks é um agente de ambiente sempre ativo no chão de fábrica que atua como um companheiro digital para sua equipe de TO – fornecendo aos técnicos um caminho desde os sintomas até a causa raiz e dando aos engenheiros de rede uma vantagem quando eles precisam intervir.
O agente ambiental local detecta o ambiente 24 horas por dia, 7 dias por semana, detecta alertas e padrões, diagnostica os sinais e prepara ações recomendadas antes que um técnico de manutenção precise perguntar. Ele detecta problemas monitorando mensagens do sistema de switch e agrupando eventos relacionados em uma janela de tempo, em vez de tratar cada alerta como um incidente separado. Ele diagnostica as causas raízes usando lógica determinística baseada em Rede industrial da Cisco experiência. Ao reunir e raciocinar sobre evidências da topologia, estado e configuração da rede, o agente identifica rapidamente a causa mais provável. E então recomenda as próximas etapas claras e sequenciadas – seja uma correção física que o técnico de TO pode seguir ou um escalonamento preciso para um problema de configuração de rede que o especialista em rede pode resolver imediatamente.
Um exemplo: Uma máquina na área de embalagem para repentinamente. O agente detecta um problema com a conexão de fibra do switch de acesso, coleta a interface e o estado do SFP e determina que o SFP na porta 1/1 está sofrendo degradação do sinal, provavelmente devido à poeira ambiental bloqueando o sinal. O alerta informa ao técnico de OT exatamente qual switch e porta foram afetados e fornece uma solução física clara: limpe e recoloque o módulo SFP. Sem o agente, esse mesmo problema teria sido relatado como “falha de comunicação” pelo técnico de OT, encaminhado à equipe de especialistas em rede e diagnosticado horas depois.
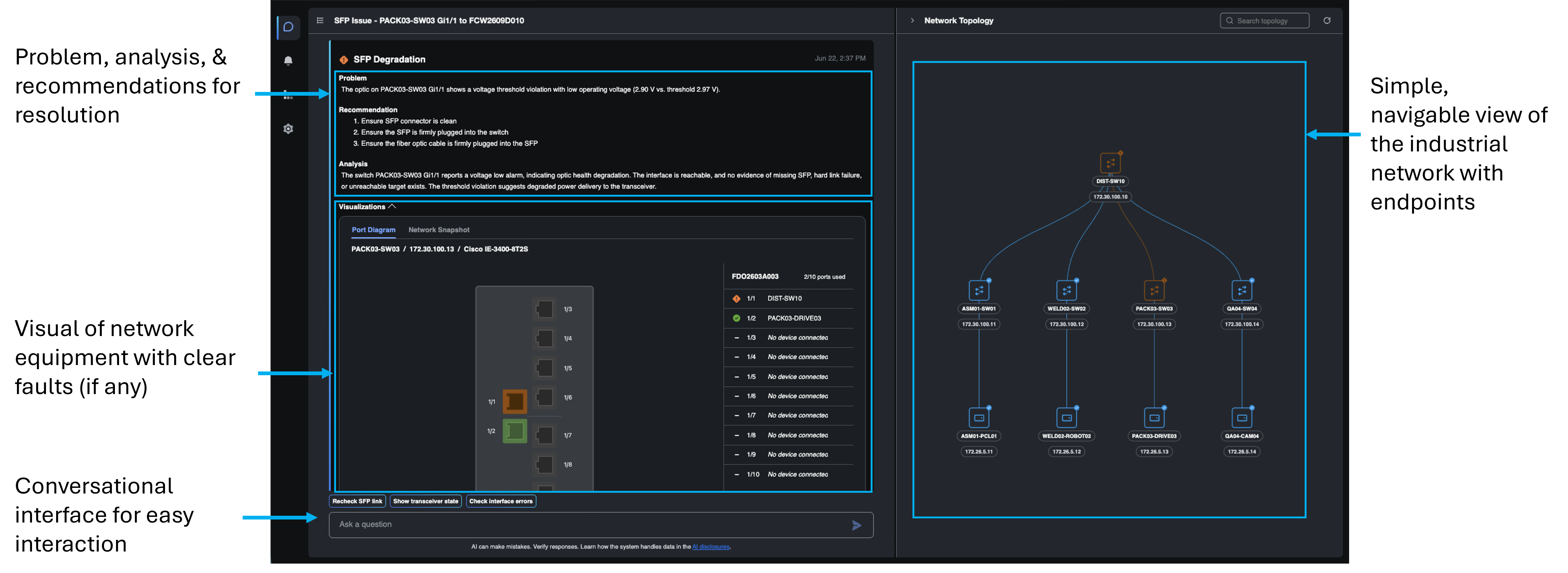
O agente lida com os problemas mais comuns enfrentados no chão de fábrica – abrangendo falhas físicas e interrupções operacionais – por meio da lógica de diagnóstico baseada em evidências:
- Falhas em cabos e fibra óptica: Detecta a instabilidade do link e determina se a causa é física, como um cabo ou módulo de fibra óptica danificado. Em caso de suspeita de danos no cabo, ele pode executar um teste de diagnóstico do cabo (com consentimento do técnico) para identificar a distância da falha em relação ao switch.
- Ponto final dispositivo off-line: Investiga razões não físicas pelas quais um endpoint parou de se comunicar, como incompatibilidade duplex, endpoint movido para uma porta de switch diferente com incompatibilidade de VLAN ou IP duplicado devido a configuração incorreta de L2NAT.
- Alimentação pela Ethernet (PoE) falhas: Verifica o status do fornecimento de energia, o orçamento disponível, os eventos de energia recentes e o status de aplicação para determinar se a causa é uma falha de política no nível da porta ou um orçamento de energia do switch insuficiente.
- Falhas na fonte de alimentação do switch: Monitora falhas na fonte de alimentação, qualidade da energia de entrada e revela a perda de uma fonte de alimentação redundante.
- Problemas de estabilidade do switch: Monitora a alta utilização de memória ou CPU, avisa que um processo está consumindo ciclos de CPU, permitindo que os técnicos escalonem com dados de diagnóstico.
Perguntas operacionais diárias
Além dos alertas proativos, o agente ajuda Equipes de AT responda a perguntas comuns sem precisar fazer login em um switch e executar comandos CLI. As equipes de TO podem selecionar um switch e iniciar uma conversa com ele para obter dados operacionais e de configuração em tempo real. O agente também sugere os prompts mais relevantes com base no dispositivo e no contexto. Os especialistas em rede podem etiquetar os dispositivos com nomes, locais e áreas de produção familiares (por exemplo, “soldador da linha 1”), para que as equipes de TO possam consultar interruptores usando linguagem OT em vez de endereços IP ou nomes de host.
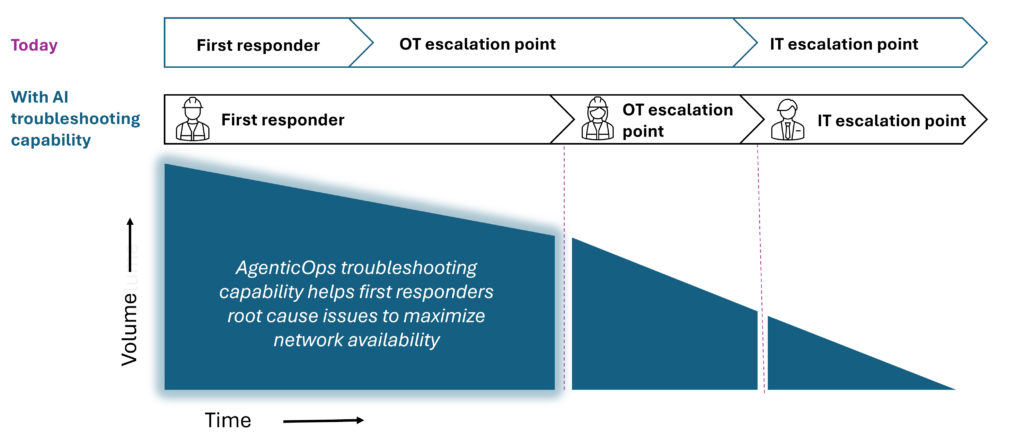
Como disse um especialista em rede de OT de um cliente de um teste alfa inicial: “Isso me ajudará a dormir melhor à noite — reduzirá os escalonamentos durante os testes e a atualização”. A solução de problemas de IA para redes industriais foi projetada para preencher a lacuna entre os sintomas e as causas raízes no chão de fábrica — reduzindo escalações, reduzindo os tempos de resolução e mantendo a produção em movimento.
A promessa da IA física depende inteiramente da maximização do tempo de atividade da rede. A solução de problemas de IA para redes industriais capacita suas equipes de TO a reduzir o tempo de inatividade e proteger a base para esta nova era.
Se você estiver interessado em moldar a próxima fase do agente e obter acesso, junte-se ao programa beta hoje.
Saber mais