Os clusters de IA estão se tornando uma infraestrutura compartilhada. Neoclouds, equipes de plataformas empresariais de IA, organizações de serviços financeiros, equipes de ciências biológicas e grupos de pesquisa precisam compartilhar a capacidade da GPU. Essa infraestrutura compartilhada pode sofrer com menor monetização, maior complexidade operacional e controle e visibilidade limitados entre locatários, cargas de trabalho, hosts e estrutura da rede.
EVPN/VXLAN é a base prática da rede. Ele fornece segmentação de sobreposição com escopo de locatário usando VRFs, VNIs, diferenciadores de rota e destinos de rota. No entanto, a segmentação com reconhecimento de locatário não é uma segmentação com reconhecimento de trabalho. O agendador entende os trabalhos; a rede normalmente entende rotas, interfaces, filas, descartes e fluxos.
Por que os clusters de IA precisam de multilocação
Clusters de GPU dedicados são simples de isolar, mas são ineficientes para operar em escala. À medida que as propriedades da GPU crescem, as organizações desejam um pool de recursos compartilhados que possa atender a várias equipes, clientes e classes de carga de trabalho sem forçar cada grupo em seu próprio cluster físico. Caso contrário, um grupo pode ter GPUs presas em uma ilha dedicada enquanto outro espera na fila.
O requisito aparece em vários padrões:
- Um provedor de GPU como serviço mapeia cada locatário para um cliente externo com seu próprio endereço e domínio de política (isolamento por cliente, mantendo o pool de GPU compartilhável).
- Uma equipe de plataforma empresarial mapeia locatários para desenvolvimento, teste, ajuste fino de produção, avaliação de modelo ou análise regulamentada (limites de ambiente consistentes sem construir clusters separados).
- Um departamento de serviços financeiros separa análises de fraude, modelagem de risco e cargas de trabalho de pesquisa em um cluster de treinamento (limites de controle e auditabilidade mais fortes sem duplicação de ilhas de GPU).
- Uma organização de pesquisa atribui capacidade de GPU compartilhada a grupos de pesquisa independentes (cota, uso e responsabilidade de solução de problemas mais claros em projetos concorrentes).
É por isso que a multilocação não pode parar na alocação de computação. O treinamento distribuído depende da comunicação leste-oeste da GPU, normalmente em malhas Ethernet, de modo que a rede se torna parte integrante do limite de isolamento e desempenho.
Como a indústria resolve isso hoje
A multilocação atual de IA geralmente é implementada em três camadas:
- Camada de orquestração e agendador. Plataformas baseadas em Kubernetes, sistemas de orquestração em nuvem GPU e agendadores Slurm definem o modelo de propriedade lógica para o cluster. Eles rastreiam locatários ou projetos, usuários, filas ou namespaces, solicitações de trabalho, posicionamento de nós e alocação de GPU. Por exemplo, o locatário A pode enviar o trabalho 100 solicitando oito GPUs em dois servidores, enquanto o locatário B envia o trabalho 200 solicitando quatro GPUs em um conjunto diferente de nós. Por exemplo, em uma plataforma de orquestração como Rafay, a plataforma pode possuir a integração do locatário e a intenção de infraestrutura, enquanto o agendamento real do trabalho pode acontecer no Kubernetes, Slurm ou em um agendador operado pelo locatário.
- Camada de isolamento do host. O host impõe o limite do dispositivo local para cada carga de trabalho. Se um locatário receber servidores inteiros, o isolamento será mais simples porque o servidor, o conjunto de GPU e o conjunto de NIC podem ser tratados como uma unidade de propriedade do locatário. Se vários locatários ou trabalhos compartilharem GPUs no mesmo servidor, o tempo de execução deverá expor apenas os dispositivos GPU atribuídos e vincular as bibliotecas de comunicação da carga de trabalho, como NCCL ou UCX, aos NICs pretendidos. Esse mapeamento do lado do host é importante porque um servidor GPU pode ter vários NICs conectados a diferentes switches ou segmentos de rede voltados para o locatário. A segmentação de malha pode isolar o tráfego assim que ele entra na rede, mas não pode corrigir uma atribuição local incorreta onde a carga de trabalho pode usar a GPU ou NIC errada.
- Camada de segmentação de rede. EVPN/VXLAN fornece segmentação escalonável de locatários em toda a malha. A VXLAN encapsula o tráfego do locatário e usa VNIs para identificar o segmento de sobreposição ou domínio de roteamento. A EVPN usa o BGP para anunciar a acessibilidade do endpoint e do prefixo e para controlar quais VTEPs importam as rotas de um locatário por meio de destinos de rota. Em uma malha de IA roteada, um locatário geralmente mapeia para um VRF e um ou mais VNIs, com diferenciadores de rota mantendo as rotas de locatário exclusivas e os alvos de rota controlando a política de importação e exportação. Isso permite sobreposição de espaço de endereço de locatário e acessibilidade com escopo em uma base compartilhada.
ACLs ou ACLs de grupos de segurança podem adicionar políticas de origem e destino, especialmente em designs brownfield L3 ou onde a malha ainda não pode consumir uma identidade de carga de trabalho mais rica. Sua limitação é a escala operacional: as políticas ACL e VRF estáticas ou atualizadas manualmente não acompanham naturalmente as rápidas mudanças nas colocações de empregos de IA.
Juntas, essas camadas fornecem um modelo viável em nível de locatário. A lacuna restante é o contexto do trabalho: a rede geralmente pode ver o contexto do locatário, interfaces, rotas, filas e contadores, mas não o trabalho específico do agendador em execução dentro de um locatário. A segmentação do locatário em si não isola automaticamente o Trabalho 100 do Trabalho 101 dentro do mesmo locatário, a menos que a identidade do trabalho também seja transportada, derivada ou programada na política de rede.
Integração do Cisco Nexus One com AI iplataformas de orquestração
O Cisco Nexus One está bem posicionado como a base mais ampla para tornar as estruturas de IA com reconhecimento de locatário mais determinísticas. Nesta arquitetura, o Nexus One é a superfície completa de automação, integração e visibilidade da malha para toda a malha.
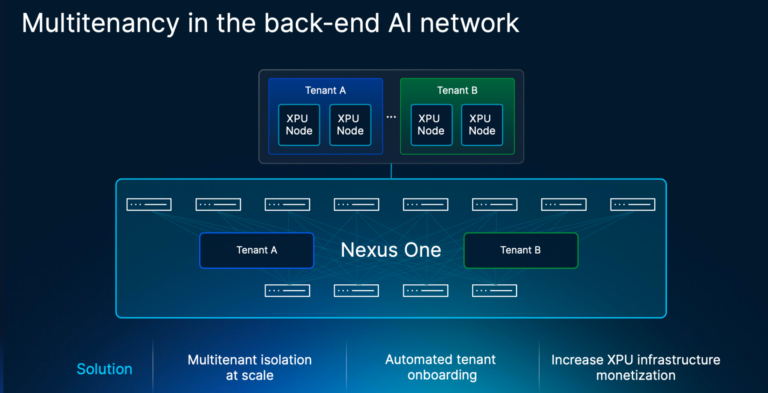
Nexus One pode fornecer contexto de topologia de malha para uma IA infraestrutura plataforma de orquestração como Rafay por meio de fluxos de trabalho de integração ou APIs. Isso permite que as equipes mapeiem VRFs, VLANs e atribuições de portas de locatários diretamente para um locatário, em vez de gerenciá-los apenas como um rótulo abstrato de locatário.
Além disso, o Nexus One amplia o modelo além do provisionamento. A visibilidade no nível do locatário pode mostrar o caminho da malha do locatário e sinais de saúde relevantes, como congestionamento, quedas e assim por diante. Isso complementa a observabilidade do trabalho de IA: visualizações com reconhecimento de trabalho podem correlacionar agendador, topologia, óptica, telemetria de GPU, análise e anomalias, enquanto a aplicação de ID de trabalho específica do locatário permanece um recurso de política separado voltado para o futuro.
Consciente do inquilino não está ciente do trabalho
A segmentação de locatários responde à pergunta: “Qual cliente ou organização possui esse tráfego?” As operações de IA muitas vezes precisam de: “Qual trabalho de treinamento está criando ou experimentando esse tráfego dentro de um locatário?”
Essa distinção é importante para a segmentação e também para a solução de problemas. Um agendador pode identificar o trabalho, os nós alocados, as GPUs e o estado do tempo de execução. A rede pode identificar interfaces, rotas, filas, quedas, marcas ECN, eventos PFC, integridade óptica e caminhos. Sem correlação, os operadores devem conectar manualmente estas duas visualizações.
O resultado é um problema operacional comum: a estrutura mostra um uplink ativo ou uma interface com perdas, enquanto a equipe da plataforma vê um trabalho de treinamento lento. O elo perdido é a identidade da carga de trabalho no modelo operacional de rede.
Direção futura: segmentação com reconhecimento de AI Job-ID
A direção de segmentação com reconhecimento de Job ID – tecnologia com patente pendente da Cisco – é o próximo passo lógico. (Observe que isso descreve nossa direção arquitetônica, não um recurso de envio.) O objetivo é infraestrutura orquestrador (como Rafay) e o planejador (como Slurm) pretendem transportar a identidade do locatário e a identidade do trabalho para o controle de malha e o modelo de plano de dados.
Nesse modelo, o controlador de malha traduz a intenção do trabalho em política. O plano de dados do switch transporta ou deriva um ID de trabalho, por exemplo, por meio de bits de GPO VXLAN, e impõe que apenas endpoints no mesmo locatário e trabalho autorizados possam trocar tráfego RoCEv2.
Os benefícios esperados são operacionalmente importantes:
- Operações mais simples, porque as equipes podem raciocinar sobre inquilinos e trabalhos em vez de traduzir cada mudança em objetos de rede estáticos – crucial para equipes de NetOps e operações de malha.
- Visibilidade mais profunda, porque quedas, congestionamentos, caminhos e óptica podem ser correlacionados ao contexto da carga de trabalho, em vez de apenas a interfaces ou VRFs de locatários, o que é benéfico para engenharia de plataforma e equipes de SRE.
- Segmentação mais granular, porque a política pode seguir o ciclo de vida de um trabalho em vez de parar no limite do inquilino, o que é importante para as equipes de segurança, conformidade e governança de inquilinos.
Essa abordagem é baseada em padrões abertos – e não em uma sobreposição proprietária. EVPN/VXLAN é definido pela IETF, e a Opção de Política de Grupo (GPO) segue o mesmo caminho: um mecanismo definido pela IETF que codifica um identificador de grupo/política no cabeçalho VXLAN junto com o VNI, que o Cisco NX-OS implementa em alinhamento com a especificação aberta. O escopo do locatário (VNI) e o escopo da carga de trabalho/trabalho (GPO) são, portanto, expressos em construções que uma estrutura compatível com os padrões pode interpretar, permitindo que os operadores evoluam da aplicação consciente do locatário para a aplicação consciente do trabalho, sem uma empilhadeira de estrutura.
Exemplo técnico: inquilino e limites de trabalho
Considere um ambiente de GPU como serviço com dois clientes, o locatário A e o locatário B. Cada locatário é mapeado para seu próprio VRF/VNI na malha EVPN/VXLAN. A segmentação em nível de locatário impede que o locatário B alcance o locatário A.
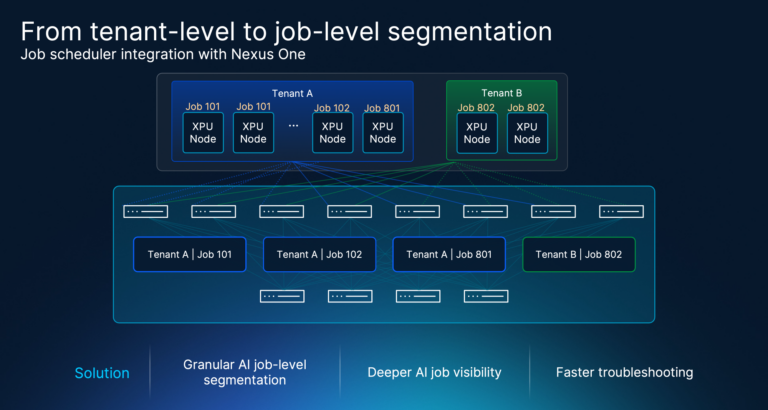
Agora suponha que o locatário A execute dois trabalhos de treinamento simultâneos. A tarefa 100 usa GPUs nos servidores 1 e 2. A tarefa 101 usa GPUs diferentes na mesma malha compartilhada. O EVPN/VXLAN em nível de locatário ainda trata ambos os trabalhos como tráfego do locatário A. A segmentação com reconhecimento de ID de trabalho adicionaria outra dimensão de aplicação: os endpoints do Job 100 poderiam trocar tráfego RoCEv2 com outros endpoints do Job 100, mas não com endpoints do Job 101, mesmo dentro do mesmo locatário.
Essa é a mudança arquitetônica: EVPN/VXLAN continua sendo a base do locatário, enquanto o Job ID se torna a política futura em nível de carga de trabalho e o atributo de observabilidade.
Avançando a segurança da segmentação em nível de locatário até em nível de trabalho
A multilocação de data centers de IA começa com a segmentação de locatários EVPN/VXLAN, mas não termina aí. O modelo operacional mais forte combina provisionamento com reconhecimento de topologia, aplicação em nível de locatário e visibilidade de ponta a ponta hoje, evoluindo em direção à segmentação com reconhecimento de Job ID à medida que a integração do agendador e do orquestrador amadurece.
Se você estiver projetando um cluster de IA compartilhado hoje, a EVPN/VXLAN com reconhecimento de locatário é a base. A aplicação consciente do trabalho e a observabilidade são a próxima fronteira.
Agradecimentos especiais a Ramesh Ponnapalli e sua equipe, cuja liderança em engenharia foi fundamental para dar vida a essa tecnologia.
Recursos adicionais: